| 编辑推荐: |
本文主要介绍了什么是tdd、传统开发方式、tdd步骤及例子,希望对您的学习有所帮助。
本文来自于csdn,由linda编辑、推荐。 |
|
1、什么是tdd
我第一次接触tdd这个概念,是在<<代码整洁之道>>中,作者鲍勃大叔在书中,写了一些关于测试代码的代码规范,其实就提到了有关tdd三定律:
- 定律一: 在编写不能通过的单元测试前,不可编写生产代码
- 定律二: 只可编写刚好无法通过的单元测试,不能编译也算不能通过
- 定律三:只可编写刚好足以通过当前失败测试的生存代码
我第一次读到这三个定律时,不能说是毫无头绪,只能说是一脸懵逼。 
完全不知道作者想表达啥意思,也没有案例代码。
对此,我不得不网上查阅的很多相关文章,最后总结出来。
tdd测试驱动开发,就是先写测试用例,再去开发功能。
这里测试驱动开发里的驱动是做动词,不是名词
好了,现在如果别人问你tdd是什么,你就可以直接这样告诉他。
2、传统开发方式
我们传统开发一个功能是这么开发的?
传统编码方式
需求分析,想不清楚细节,管他呢,先开始写
发现需求细节不明确,去跟业务人员确认
确认好几次终于写完所有逻辑
运行起来测试一下,靠,果然不工作,调试
调试好久终于工作了
转测试,qa 测出 bug,debug, 打补丁
终于,代码可以工作了
一看代码烂的像坨屎,不敢动,动了还得手工测试,还得让 qa 测试,还得加班…
传统的开发方式,都是以开发为主,直接开始编写代码,代码出了问题,再去改,多改几次,你就会觉得这代码简直就是屎山,想重构一下,又怕出新的问题。 3、tdd步骤
而tdd测试驱动开发是怎么做的呢?
tdd要求我们先根据需求去拆分任务,把一个大的任务拆分位各个模块,也就是一个个的函数,我们再去为这些函数去编写最小的测试,再去写能让这个最小的测试通过的最小的实现。
tdd的生命周期图如下。 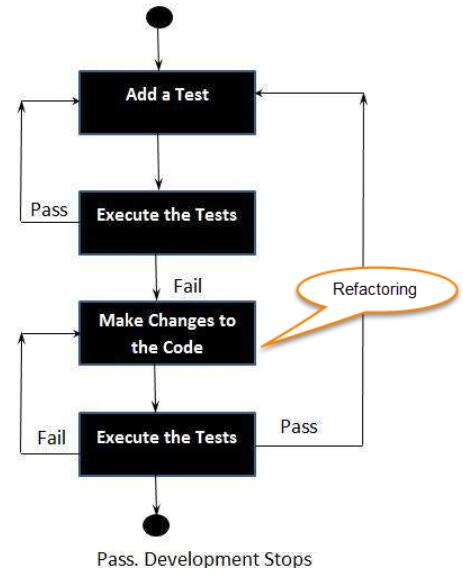
这样做的好处是:
1、有助于我们提前澄清需求
2、可以通过单元测试断言的诊断机制快速得出反馈
3、当我们写完了所有的需求,会发现所有的需求都会被测试覆盖了 4、举个例子
正所谓,光说不练,假把式;下来我们来整个简单的例子去理解一下测试驱动开发;
假如我需要写个功能,分析用户上传的文本中,每个单词的数量,并且按照数量倒序排序,这个应该怎么实现:
比如说文本如下:
hello world
hello csdn
hello boy
my name is boy
is is
|
那输出就是:
hello 3
is 3
boy 2
world 1
csdn 1
my 1
name 1
|
如果是新手或者是完全不懂代码设计的人拿到这样的功能,可能会这样写:
public static
void main(string[] args) throws exception{
string words = "";
file file=new file("word.txt");
scanner sc=new scanner(file);
while(sc.hasnextline()){
string line=sc.nextline();
words = words line " ";
}
system.out.println(words);
string[] wordarrays = words.split(" ");
hashmap hashmap = new
hashmap<>();
for(int i=0;i
set wordset = hashmap.keyset();
if(wordset.contains(wordarrays[i])){
integer number=hashmap.get(wordarrays[i]);
number ;
hashmap.put(wordarrays[i],number);
}else{
hashmap.put(wordarrays[i],1);
}
}
system.out.println("统计单词------------------");
list>
list = new arraylist>(hashmap.entryset()); //转换为list
list.sort(new comparator>() {
@override
public int compare(map.entry
o1, map.entry o2) {
return o2.getvalue().compareto(o1.getvalue());
}
});
system.out.println(list);
}
|
好了,写完了,让我们运行一下:
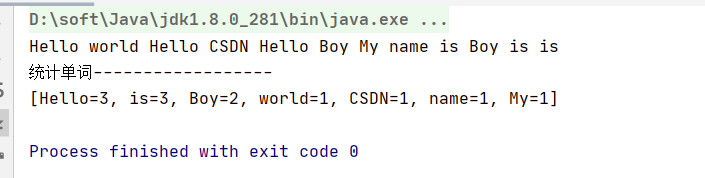
运行结果貌似也没有问题,好了提交代码。
真的没有问题吗?统计单词的数目也没有问题,但是,如果后期,你要对这段代码做维护,要去修改这段代码,这段代码读起来是什么感觉?在我看来,这段代码,就是屎山。
代码里几乎完全没有注释,读这段代码,得从头开始往下读,如果其中一段代码出了问题,你必须在整段代码中寻找错误,非常浪费时间。
让我们来试试看tdd的写法,tdd要求首先要把一个功能,去拆分分成各个小功能,然后去为这些小功能写测试用例。
这个统计单词数目的代码应该怎么拆分,试着拆分成小功能一下(这里要注意一下,同样的功能,在拆分模块的时候,不同的人选择的拆分方法可能不同,一千个人里有一千个哈姆雷特,一千个人里也有一千种拆分方法) 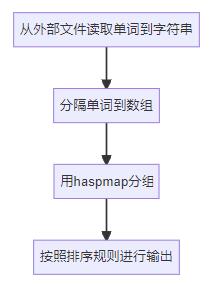
拆分好后,我们就可以为这些功能编写测试用例了,
我们先编写测试用例,用assert断言测试用例是否通过,运行,我们可以看出,方法还没有进行开发,显示未通过。 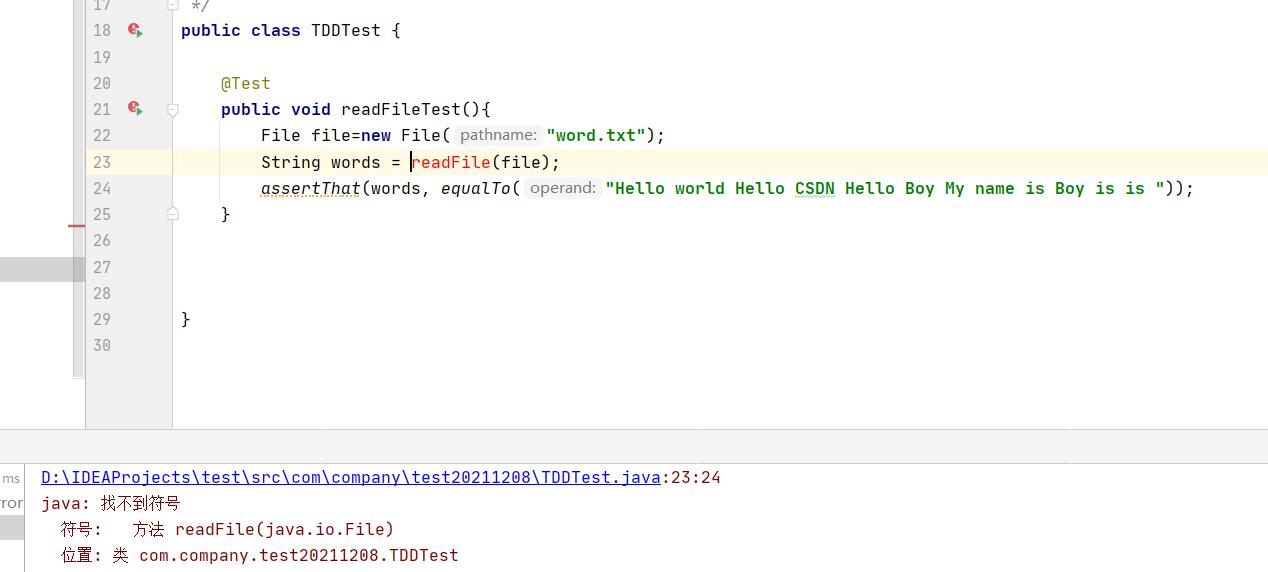
这一步,就是tdd定律二中规定的
| - 定律二: 只可编写刚好无法通过的单元测试,不能编译也算不能通过
|
下一步要做什么?我们看定律一
| - 定律一: 在编写不能通过的单元测试前,不可编写生产代码
|
定律一反过来是什么意思,不就是编写好不能通过的单元测试后,就可以开始编写生产代码了吗?
于是开始编写生产代码进行测试 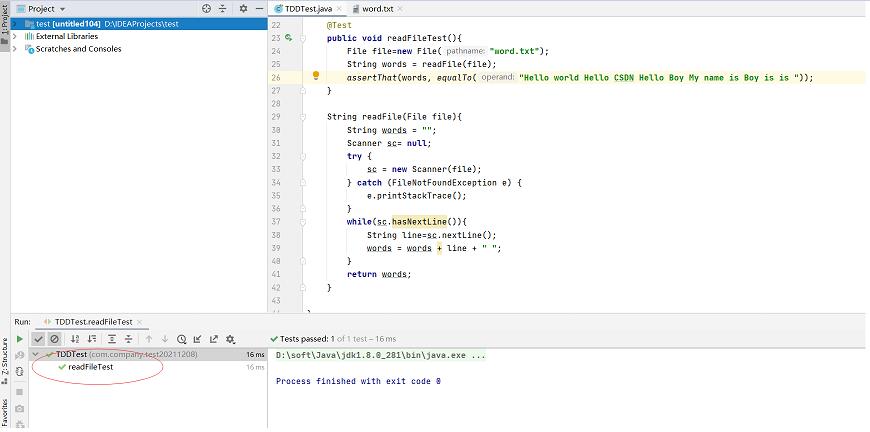
在这里,我们编写好了方法,在执行测试用例后,显示绿色,代表测试用例通过。
这时候又满足了第三定律
| - 定律三:只可编写刚好足以通过当前失败测试的生存代码
|
我们的测试用例,专门测试一个小的功能,只为了通过这个方法。
下一步我们再重复以上步骤,去tdd其他模块。
直到tdd完所有模块,我们的功能就开发完了。
代码如下:
public static
void main(string[] args) throws exception {
//读取文件
file file=new file("word.txt");
string words = readfile(file);
string[] s1 = words.split(" ");
//单词记录到hashmap
hashmap stringintegerhashmap
= grouphashmap(s1);
//排序
list> entries
= orderhashmap(stringintegerhashmap);
//输出
system.out.println(entries);
}
|
方法的代码太长,太展篇幅就不粘贴了,你看我们新的main方法,代码就比较简介,如果出了问题,只可能在这三个方法中其中,我们可以快速定位到方法中去,并且可以用之前编写的测试用例进行测试。 5、总结
关于tdd测试驱动开发,我感觉精髓就是对功能进行拆分,用测试用例去测试功能,我相信很多人,都不会去编写测试用例,代码写好后,就去页面上点几下,其实这是不太好的。因为如果这里的功能改动比较频繁,你每次去页面上通过点击的方式测试功能,你得打开浏览器,登录地址,寻找ip,为功能配置参数,这一套下来,真的非常耗费时间。
一次如果5分钟,10次就是50分钟。
而tdd建议的是什么?建议通过测试用例的方式去测试,它要求你必须编写好测试用例后再去写代码,这样就能保住,你每个小功能,都有一个测试用例,这样,之后你改一个地方,只要找到这个地方所对应的测试用例就能测试了,非常方便。
当然,tdd这种开发方法其实弊端也是很明显的,比如,大多数程序员,其实是怎么做测试的?就是直接重启项目,去页面上看看,功能对不对,测试用例?那是什么?我不是开发吗,我又不是测试。我去页面点几下测试,可能只需要几分钟,我去配置测试用例,八成等得二十分钟,所以大多数程序员可能还是会选择通过页面点击的方式去测试。
测试用例真的是没有必要的吗?如果你去新建一个maven项目,你会发送,test目录和main目录是同一级别的
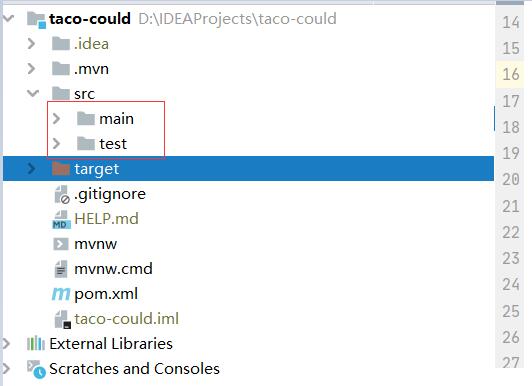
我相信在设计的时候,可能设计者(设计maven的程序员肯定是大佬中的大佬),也是认为测试用例是非常重要的,才会把test目录放在这个位置吧。
|


